As with many MacOS’isms, you have to change up your old school LINUX to work with the slightly different command syntax of the MacOS tools. Specifically in the this case xargs and sed.
xargs can be an amazingly powerful ally when automating commands line functionality, wrapping the reference command with auto-substitutions using the ‘@’ meta-character.
I’ll get to the meat of this. While trying to automated a grep -> sed pipeline, I encountered this error:
egrep -rl 'version 0.0.1' src/* | xargs -i@ sed -i 's/version 0.0.1/version 0.0.1c/g' @
xargs: illegal option -- i
It turns out that MacOS xargs like -I instead of -i.. (a quick trip to man sorted that out).
-I replstr
Execute utility for each input line, replacing one or more occurrences of replstr in up to replacements (or 5 if no -R flag is specified) arguments to utility
with the entire line of input. The resulting arguments, after replacement is done, will not be allowed to grow beyond 255 bytes; this is implemented by con-
catenating as much of the argument containing replstr as possible, to the constructed arguments to utility, up to 255 bytes. The 255 byte limit does not apply
to arguments to utility which do not contain replstr, and furthermore, no replacement will be done on utility itself. Implies -x.
Next I ran into an errors with sed.. when using the ‘edit in place’ flag -i. (yes, that makes for a confusing debug when you have the “offending” switch in two places).
egrep -rl 'version 0.0.1' src/* | xargs -I@ sed -i 's/version 0.0.1/version 0.0.1c/g' @
sed: 1: "src/com/ingeniigroup/st ...": bad flag in substitute command: 'a'
sed: 1: "src/com/ingeniigroup/st ...": bad flag in substitute command: 'a'
sed: 1: "src/com/ingeniigroup/st ...": bad flag in substitute command: 'a'
[...]
With a little testing of the individual command, and another trip to man, it took a little noodly to deduce that the error message was being generated because it was trying the sed commmand as the output file suffix and the filename as the sed command! Adding an empty string designator after sed’s -i solved this.
-i extension
Edit files in-place, saving backups with the specified extension. If a zero-length extension is given, no backup will be saved. It is not recommended to give
a zero-length extension when in-place editing files, as you risk corruption or partial content in situations where disk space is exhausted, etc.
Final Command Query
The objective was to simply hammer through the source code and update the version tag from 0.0.1 to 0.0.1c. Running egrep in recursive filename list mode ( egrep -rl ) for the string I wanted ( ‘version 0.0.1’ ) gave me a file list, which was then piped into xargs, which expanded that list into the sed command ( sed -i ” ‘s/version 0.0.1/version 0.0.1c/g’ ). And viola.. 18 files changed with just a little big of effort:
For that last 6 months I have been capturing Aviation Mode-S and ADS-b data transmissions using my own customizd STRATUX Aviation Traffic Receiver running Raspberry Pi 3b. With my modifications, the device automatically shuts down daily for a few seconds to release the current SQLite3 database, and the start up pointing at a fresh database. Once released, the database is compressed to save space and for later download (I use rsync to automate that as well).
These database files can be very big, and contain hundreds of thousands of contact events each day. When these databases are generated every day, it doesn’t take long to get a backlog of them to examine for interesting things, such as NASA aircraft and some mysterious high-flyers using spoofed identities.
Being a professional programmer and data guru, this seemed like a perfect project to open-source and use a marketing tool for my consulting. After a week of design, development and preliminary tests.. it’s ready for comment.
What it does:
The tool is purpose built for my needs, so it might not (yet) be easily used on your own Stratux database files, but I feel I’ve made a reasonable effort in the interests of ease.
Each database file is opened and checked for a number of conditions and data:
Verify database contains expected STRATUX data tables.
Select first timestamp record and report it out. Since the name of the file might not be self descriptive, this is really helpful to know the dataset’s start time:
Using Database File: './sqlite-stratux-temp'
Start: 2017-10-10 08:11:09.967 +0000 UTC
-----------------------------------------
Check dataset for obvious duplicates and remove them. It’s not uncommon for the message log to repeat a fixed position up to 5 times. Although this does not affect the current metrics, this bloats the dataset. There is an optional flag to disable this feature
Once duplicates are removed, each airframes dataset is checked for gross errors, such as changes in altitude or speed that would be possible only with alien spacecraft; records are also removed. There is an optional flag to disable this feature
10486213 -- Bad Distance 24924 --> 51857
10617769 -- Bad Distance 82039 --> 206496
10707621 -- Bad Speed 318 --> 8303
Following data repair a few metrics are pulled from the dataset, looking for interesting boundary events such as Fastest and Furthest contacts. Each record reports the Callsign or Tail Registration number (when available), and the Mode-S ICAO24 code as well as altitude, speed and distance for the specific event. Example:
FASTEST: XAOLE [0D0AAE] 43000 ft. @ 529 kts. 23 mi.
SLOWEST: NDU45 [A6EBAF] 1150 ft. @ 61 kts. 2.26 mi.
HIGHEST: XAOLE [0D0AAE] 47025 ft. @ 505 kts. 92 mi.
LOWEST: N41218 [A4DE2A] 550 ft. @ 77 kts. 1.71 mi.
CLOSEST: N6464R [A87E79] 2525 ft. @ 84 kts. 0.00 mi.
FURTHEST: N229NN [A203A9] 36000 ft. @ 472 kts. 128 mi.
Here is an example of an interesting contact captured last year along the coast of California; a high-altitude signal from a NASA 747 test aircraft almost 100 miles off the coast.
HIGHEST: NASA747 [AA0DB8] 43025 ft. @ 473 kts. 32 mi.
FURTHEST: NASA747 [AA0DB8] 43000 ft. @ 466 kts. 92 mi.
During this phase of the process, special Squawk Code events are trapped that might indicate special civil, science or military operations. Example:
**ALERT: N7253N [A9B8ED] 4403 2500 ft. @ 118 kts. SR-71, YF-12, U-2 and B-57, pressure suit flights
**ALERT: N7272N [A9C038] 4402 2075 ft. @ 116 kts. SR-71, YF-12, U-2 and B-57, pressure suit flights
**ALERT: N7274N [A9C07E] 4404 1250 ft. @ 100 kts. SR-71, YF-12, U-2 and B-57, pressure suit flights
**ALERT: N907CH [AC8967] 4442 1800 ft. @ 140 kts. SR-71, YF-12, U-2 and B-57, pressure suit flights
In the above case, N7253N, N7272N and N7274N are Department of Homeland Security Border Patrol helicopter contacts.
Here is a recent report example:
Start: 2017-10-10 08:11:09.967 +0000 UTC
-----------------------------------------
FASTEST: AFR6721 [3951C1] 32975 ft. @ 531 kts. 14 mi.
SLOWEST: N42894 [A51D07] 950 ft. @ 51 kts. 3.21 mi.
HIGHEST: JCB1 [43E9D5] 47025 ft. @ 469 kts. 34 mi.
LOWEST: N724DP [A9B2C1] 400 ft. @ 72 kts. 1.65 mi.
CLOSEST: N605CH [A7DA0C] 16200 ft. @ 400 kts. 0.02 mi.
FURTHEST: N9023N [AC7968] 33050 ft. @ 433 kts. 143 mi.
Where can you get it?
You can fork or pull the current source code from GitHub here: IngeniiCode AvMet
I have been working on distributed harvesting projects for the last 5 years. Generally the projects used a raft of AWS EC2 instances and Gearman to manage the workflow. Having recently heard of some similar solutions using AWS Lambda functions, I wanted to explore this as a possible new architecture for these projects. So.. I dug in.
The learning curve for me has been a little steep. There is a limited number of languages supported (AWS doc linked here), but the only two that came close to meeting my needs were NodeJS and Java.
Most of my project code is written in CasperJS, a NodeJS extension, so I thought that perhaps that was the path of least resistance.. but it was not clear to me how to ‘install’ PhantomJS and CapserJS components into this Lambda Function, so I switched to working with Java.
Designing the Test
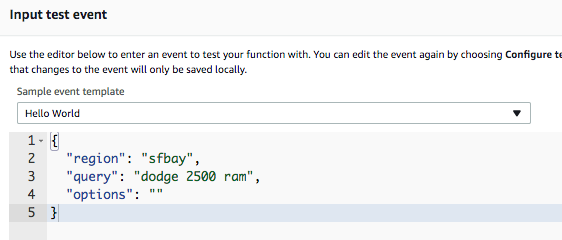
This is a VERY simple test blob, but it took me about a day to get to this point, since it was not totally clear to me how the AWS API Gateway might work and how the data is packaged/posted to the <Lambda Function. After a lot of poking around, uploading my first hunk of (totally broken) code; I was presented the a test CLI. The test CLI has only a few options or packaging up data payloads (at least for test), singular scalar string and a JSON string (which turns into an Object.. the source of the frustration I faced figuring this out).
Boiling it down, this is what the test harness input looks like, when you use the “Hello World” test case, after changing the properties to match my desired inputs:
This will work fine for my needs, I prefer JSON payloads over a fixed (brittle) set of parameters.. this lets me muck around with the internals and add more capacity without having to work about external inputs; I’m just that way.
Having decided that JSON was the payload to accept.. next I needed to write a chunk of code to accept it.
Writing the Test Code
Knowing that I would be using a Json string as my input, I’d first coded my function like this:
public String searchAuto(String json){
return String.format(“%s”,json);
}
What I discovered quickly is that the string of JSON in the test payload (which looks like this), is deserialized as a Json Object, and not a string. This required me to step up my simple test to actually deal with the data as JSON. To do this, I selected simple.JsonObject. This is where the “fun” began. Hopefully this helps you avoid spending the time I did to figure out how to get the code cleanly compile locally.. AND to run when uploaded to AWS.
NOTE: I’m not going to say this is the right way to do this.. it’s just the way it worked for me. It’s kludgy and I don’t really like having a two step process but it’s working to get my version of HELLO WORLD working.
Long story short, I needed to get copies of these three .jar files added to my project’s build path, to get things going. Where you place them in your project might vary, but in a basic NetBeans project, these are in the lib/ directory off the project root:
Locating the jars was not the simplest task either, Amazon’s horrible documentation sent me fishing around on various Github repos, but in the end.. I found them with a good ol search. I’ve linked the libs in the above block to where I sourced mine.
AWS Lambda requires use of specific handler hooks, when initiating the function. I’d like to wax poetic about what it all means but at this time, I just need a proof of concept, so using a code example.. this is the code I compiled:
public String myHandler(int myCount, Context context) {
LambdaLogger logger = context.getLogger();
logger.log(“received : ” + myCount);
return String.format(“Received value of %d”,myCount);
//String.valueOf(myCount);
}
/* search options */
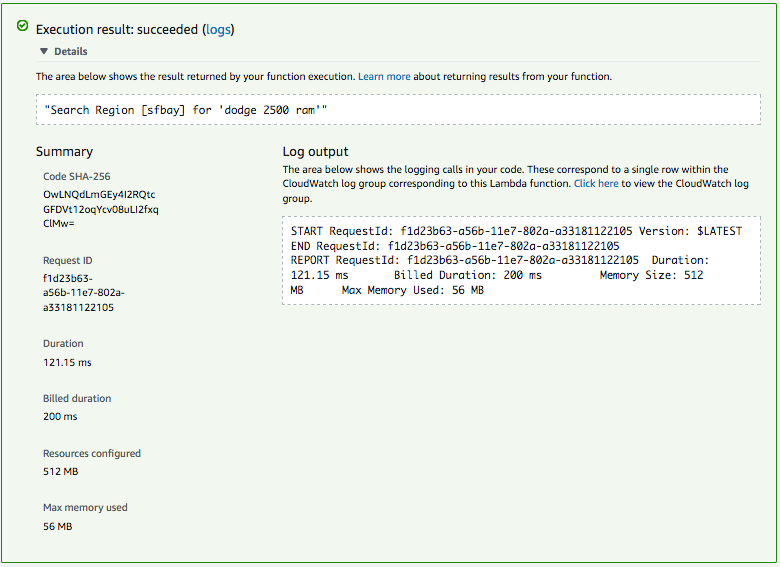
public String searchAuto(JsonObject json){
return String.format(“Search Region [%s] for ‘%s'”,json.getString(“region”),json.getString(“query”));
}
}
Beyond the Build – Packaging your Java
Again, the think the AWS documentation is pretty crappy, and this extends to every AWS service I’ve had to use. Once you figure out what I really means, they work very well.. but decoding Seattle AWS-speak (for me) is often not easy. You might be smarter than me and able to see the path right off the bat.. well.. good for you. For me and the rest of the inelastic brain crowd.. I’ll try to give you the Cliff Notes version…
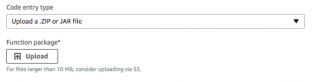
When I simply wanted to test my JAR, and I didn’t need the JSON libary, it was a simple matter of uploading the Jar file in the Lambda dialog; it looks like this:
However, uploading more than 1 jar, things start to get a little wonky. The instructions say this:
Example Gradle Config
The page also provides a rather extensive rundown on using Gradle to run your build and make the package. Since creating my own .ZIP with the files in the ‘root’ as designated didn’t work, I went Gradle. If you decide to go Gradle, here is the build file I ended up using. When I made the mistake of including the Mavin paths for AWS into the Gradle build, I ended up with ALL if the AWS .jar files being downloaded and zipped into the library, creating a 7.8 MB upload!! For a Hello World program.. INSANE! Anyhow.. this is my gradle config that changes the default Gradle configs (build.gradle text file) to work with NetBeans paths. You might need to tweak this further to your own needs:
apply plugin: ‘java’
//repositories {
// mavenCentral()
//}
sourceSets {
main {
java {
srcDir ‘src’
}
}
test {
java {
srcDir ‘test’
}
}
}
task buildZip(type: Zip) {
from compileJava
from processResources
into(‘lib’) {
from configurations.runtime
}
}
build.dependsOn buildZip
Using Gradle to run the build looks like this, run the command gradle build and you are on your way… as long as your code has a clean compile:
gradle build
BUILD SUCCESSFUL in 1s
3 actionable tasks: 3 executed
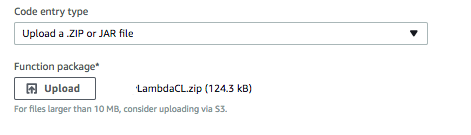
This allowed me to build a ZIP file that uploaded and worked. What I found out, was that the structure of the file is NOT really the way it was described in the docs. The contents of the zip file look like this for my project; note that when uploading this way, you are *not* packaging the .jar file for your class, but the compiled class file. Also not that it is *not* in the root of the path. With this knowledge, I can probably dispense with dual-building with Gradle and just package up the contents in this way. Hack the process!
Now, you should be able to upload your zip file. Not that a file of 10MB or more, they’d like you to spend extra money storing it on S3… (niiiiice).
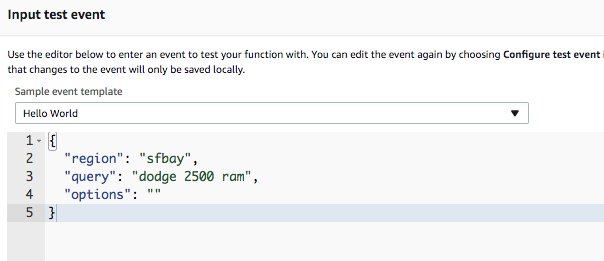
Testing your Function
Once uploaded, you can configure your test…
… and run it!
Conclusion
After a day of putting around and getting frustrated with the AWS docs that always leave (for me) gaping knowlege gaps.. I have a proof of concept test coded, compiled, uploaded and run. Now.. what needs to be sorted out is how to setup the AWS API Gateway to trigger this function… and look at how much each of those iterations will cost. With a planned execution batch that will range from 40-60 events per query.. this could add up fast.
So….. I’m not yet convinced this will function economically for my latest project; but I’m going to be testing out the concept pretty thoroughly over the coming week.
I like using the command line / shell to pass information to scripts and programs. Sure it has limitations but it’s generally pretty effective.
Each language seems to have it’s own method of handing them, and CasperJS does not seem to be any different. What I did find a little different from others, is how CapserJS splits out arguments from parameters (options in CapserJS speak).
Passing Arguments
Passing arguments is a fairly simple affair. His an example of passing some arguments on the command line to a screen capture utility I’m working on:
This would result in ‘url’ = ‘http://www.someplace.com’ and ‘mode’ = ‘save_local’. Pretty straight forward. One major drawback, you must know the order of the parameters, add a new one, get one out of place and the entire house of cards collapses.
There is a better way!
Passing Parameters (options)
Passing options is a fairly simple affair as well. His an example of passing some option on the command line:
This would result in ‘url’ = ‘http://www.someplace.com’ and ‘mode’ = ‘save_local’. Now, you do not need to worry about ordering of options, and adding more options doesn’t mean that you’ll have to worry about re-coding the variable localization, ordering etc. It’s also CLEAR to any user how the cli is formatted.
Now, go forth and parse, screen capture and automate your testing until your heart is content!
Woo.. I love *NIX, especially ‘sed’ (and awk too for that matter). Wonderful things you can do to automated your programming, speed up development and really REALLY cut down on cut-paste errors.
Today’s task, was to take this list of tables… and generate a single bit fat T-SQL command to truncate them all.. *however* these tables might not exist in a given environment so each Truncate is wrapped in a test to make sure the table is there. If it’s not there, nothing to do, not to mention avoid a potential fatal error trying to truncate a non-existent table.
— Truncate table FCT_CRIMINOGENIC_NEED_TOP_DOMAINS
IF EXISTS (SELECT * FROM sys.objects WHERE NAME = ‘FCT_CRIMINOGENIC_NEED_TOP_DOMAINS’)
BEGIN
TRUNCATE TABLE FCT_CRIMINOGENIC_NEED_TOP_DOMAINS
END
— Truncate table FCT_DETENTION_RISK_RESPONSE_DETAILS
IF EXISTS (SELECT * FROM sys.objects WHERE NAME = ‘FCT_DETENTION_RISK_RESPONSE_DETAILS’)
BEGIN
TRUNCATE TABLE FCT_DETENTION_RISK_RESPONSE_DETAILS
END
— Truncate table FCT_DETENTION_RISK_RESPONSE_FULL
IF EXISTS (SELECT * FROM sys.objects WHERE NAME = ‘FCT_DETENTION_RISK_RESPONSE_FULL’)
BEGIN
TRUNCATE TABLE FCT_DETENTION_RISK_RESPONSE_FULL
END
The Sed Command
sed ‘s#^\(.*\)#– Truncate table \1 \’$’\nIF EXISTS (SELECT * FROM sys.objects WHERE NAME = \’\\1\’) \\’$’\n BEGIN \\’$’\n TRUNCATE TABLE \\1 \\’$’\nEND \\’$’\n#g’ MY_INPUT_FILE
Secret Sauce Ingredients
Setting up the string match. In this case it was simple.. I wanted the entire line which is represented with .*
\(.*\)
This loads the matching string into an internal register in ‘sed’ that can be references as ‘1’ within the output replacement expression. This is what it looks like in the command:
\1
Adding a newline in the output.. this was the big trick, and requires dropping into the shell to generate the desired output. The string in the command looks like this:
\’$’\n
You may notice after the first drop into the shell, the escaping has to be doubled for the substitution and the newline…
\\1 \\’$’\n
I cannot speak to the reason for this, but that is what I encountered and why the substitutions change in the latter part of the string. You may find that is not necessary, or might cause an issue in your environment. Adjust as necessary.
Why.. why? Just because it’s useful when pages had dynamic content in javascript. Is there a way to subsequently evaluate the javascript parsed.. that’s for another article, but for now, I’m going to assume you have node.js installed, and you have at least come idea of how to use it.
The idea
Finding all the <script> nodes in an HTML page, rendered using
‘request.get()’
.
In the example, url (in this case www.amazon.com) is resolved and the HTML loaded. The loaded HTML is then passed to cheerio using this expression:
.. then iterated upon using the .each( ..) object method.
$(‘script’).each( function () {…
In the very simple example the follows the script is logged to the console (STDOUT) for display. In an more advanced and useful implementation, the returned javascript would be interacted with, parsed or some other action taken.
The Script
// MAKE REQUIREMENTS
var request = require(‘request’);
var cheerio = require(‘cheerio’);
// Local Vars
var url = ‘https://www.amazon.com’;
// Define the requests default params
var request = request.defaults({
jar: true,
headers: { ‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:24.0) Gecko/20100101 Firefox/24.0’ },
})
// execute request and parse all the javascript blocks
request(formUrl, function (error, response, html) {
if (!error && response.statusCode == 200) {
// load the html into cheerio
var $ = cheerio.load(html,{ normalizeWhitespace: false, xmlMode: false, decodeEntities: true });
// iterate on all of the JS blocks in the page $(‘script’).each( function () {
console.log(‘JS: %s’,$(this).text());
});
}
else {
console.log(‘ERR: %j\t%j’,error,response.statusCode);
}
});
While everyone waits for Apple to release a patch for the ShellShock bug, one of the maintainers of BASH assisted with detailing out how to patch BASH (and SH) on OSX to prevent the Vuln. This comes from the helpful Apple section of Stack Exchange.
NOTE: To perform this patch you MUST be granted sudo privs on your machine — if not you won’t be able to move the new files into the required location.
Testing to see if you are vulnerable
First things first.. see if you are vulnerable by checking your version of BASH. The desired version is this; GNU bash, version 3.2.54:
If you are not seeing that, then you should check to see if you have the vuln. When I checked my updated version of OX Mavericks, I was on Bash 3.2.52 and it was vulnerable to the exploit.
If you see the word ‘vulnerable’ when you run this, your at risk! env x='() { :;}; echo vulnerable' bash -c 'echo hello'
This is a PASS (OK): env x='() { :;}; echo vulnerable' bash -c 'echo hello'
hello
This is a FAIL: env x='() { :;}; echo vulnerable' bash -c 'echo hello'
vulnerable
hello
Time to get down to patching
This process is going to require you to do some command line work, namely compiling bash and replacing the bad versions with the good ones. If you are NOT comfortable do that.. best to wait for Apple to create the installable patch. If your geek level is above basic, continue forward:
First, agree to using xcodebuild
If you have no run xcodebuild, you are going to need to run it, then agree to the terms, before you’ll be able to finish this build. I recommend you run it NOW and get that out of the way: xcodebuild
Set environment to NOT auto-include
This capability is part of the reason the exploit exists. It’s highly recommend you turn this on before starting the build. Ignore at your own peril. This parameter is used in the build stage for two patches:
export ADD_IMPORT_FUNCTIONS_PATCH=YES
Make a place to build the new objects
I dropped everything into the directory ‘new-bash’… and did it thus. NOTE: I am not using sudo, (yet)
mkdir new-bash
Download base-92 source
Move to that directory and download the the bash-92 source using good old curl and extract the compressed tarball:
cd new-bash
curl https://opensource.apple.com/tarballs/bash/bash-92.tar.gz | tar zxf -
Get the patch packages next
CD to the source directory for bash, and then download 2 patch packages:
cd bash-92/bash-3.2
curl https://ftp.gnu.org/pub/gnu/bash/bash-3.2-patches/bash32-052 | patch -p0
curl https://ftp.gnu.org/pub/gnu/bash/bash-3.2-patches/bash32-053 | patch -p0
Start creating the patches
Execute these two commands, in order two build and apply the two patches:
[ "$ADD_IMPORT_FUNCTIONS_PATCH" == "YES" ] && curl http://alblue.bandlem.com/import_functions.patch | patch -p0
[ "$ADD_IMPORT_FUNCTIONS_PATCH" == "YES" ] || curl https://ftp.gnu.org/pub/gnu/bash/bash-3.2-patches/bash32-054 | patch -p0
Start building!
Traverse back up the tree and start running the builds. It is recommended that you NOT run xcodebuild at this point. Doing so could enable root powers in the shell and that is something that you certainly do not want!
xcodebuild
OK.. PATCH MADE!
At this point you have a new bash and sh object build to replace the exploitable ones. Backup your old versions, move these into place and you are now safe.
# Test your versions:
build/Release/bash --version # you should see "version 3.2.54(1)-release"
build/Release/sh --version # you should see "version 3.2.54(1)-release"
Now clean up the local mess
Now the local directory where you build bash is no longer needed. I don’t like to leave cruft around on my system that creates a confusing environment. Removing the source tree is my last task. You can leave it if you like, but if I need to do this again I’m going to perform a full fresh rebuild, so this will not be re-used.
cd
rm -rf new-bash
YOU ARE DONE!
BIG HUGE THANKS TO ALL THAT DID THE REAL WORK HERE.. the people maintaining bash, the people that post awesome solutions to StackExchange and all the other fantastic resources on the net!
With the kick-off of my new Start-Up Company (this is #8 for me, since I started my first company in 1984, Bay Auto Electronics), after taking 10 years to pursue some potentially lucrative (only time will tell if those efforts ever pay off, I’m not holding my breath) employment opportunities in the Internet Security / Anti-Fraud sector.
The short term plan is for that work to continue on a project consulting basis for the remainder of the year (that is the plan.. always subject to change), however in addition to that I’ve taken on two additional clients with very diverse project needs. Those needs need to be carefully manged and time properly allocated to each of these clients and their projects.
In the past, I’ve had adequate success using Work Diary spreadsheets to call out time per project and how it was spent within each of these projects. I continue to do that now. However I want a more useful, powerful and visual tool to track efforts, tasks, sprints, milestones, etc. And in addition to that I want to expose that information to each of my clients so they can get a status update on their projects near-real time, any time, day or night, and also help project their expenses as the projects move forwards.
To make this goal a reality, I have decided to Trail out a tool recently implemented at one of my former employers. It’s name is JIRA. And so far, having only used it there for 30 days or so, I’m impressed. Here is a screen shot of my current JIRA Dashboard (projects, names etc changed to protect the innocent, etc. etc. etc.).
My Sample JIRA Project Dashboard
All that said, and after communicating with one of the helpful JIRA engineers to make sure this tool would do what I want, and provide information for my clients as well, all on one system I host, the decision was made to move forward to the project!
To get further feet-wet, I’m first downloading the distributions for both MAC and LINUX. Initially I will be installing this on a MAC workstation to get the project defines, users entered etc. To test out the waters and learn on a test environment before cutting it loose in the wild. Eventually this will roll out with a public facing (for those with the right credentials) interface for project tracking. One of the first projects that I’ll be defining in my private installation will my forthcoming programming book. After 20+ years as a professional developer, trainer, sales engineer, IT Director and Entrepreneur, there are unique perspectives I can bring to the practice of programming. Keep any eye out for announcements on this by September! 🙂
Getting JIRA – downloading distributions
The current distributions, as of this blog, are located here: http://www.atlassian.com/software/jira/download JIRA Download Page
NOTE: – regarding OSX
As noted in the pages, installing on OSX is only suitable for evaluation purposes. That’s OK, not a big issue, I’ll have hardware available to host it in the next two weeks. Until then, running a local evaluation will be just fine. Unfortunate that the product can support Windows, but it’s not a surprising point since Apple has shuttered it’s proper Server production lines and is no only shipping MacMini servers and those horrendous beasts know as MAC Pro workstations. There IS A LOT to be said for 19″ rack compatible system, when it comes to REAL CORPORATE operations
Installing on MAC (in this case a laptop of all things)
I selected this package named: JIRA 5.0.6 (TAR.GZ Archive).
Instead of just creating more muck in my Downloads directory, I created a dedicates Atlassian directory under Applications.
I moved the file there and ran the extraction:
First order of business was setting my JIRA Home Directory. The instructions are found here at this link: https://confluence.atlassian.com/display/JIRA050/Setting+your+JIRA+Home+Directory.
I chose to use the LINUX configuration script located at bin/config.sh to get JIRA setup. This I ran from a console:
You must also setup an environmen var that points to the same directory you configured using the JAVA Config dialog. Since I use the ‘bash’ shell (please, no need to comment on the virtues of ksh, sh, bash.. whatever… I’m not going to listen), I edited my .bash_profile adding these two lines:
## Required Element for JIRA
export JIRA_HOME=/Applications/Atlassian/atlassian-jira-5.0.6-standalone
With that little step completed, I returned to the bin/ directory where I installed JIRA and lit up the night:
FotoCorsa-3:bin david$ ./start-jira.sh
To run JIRA in the foreground, start the server with start-jira.sh -fg
executing as current user
.....
.... .NMMMD. ...
.8MMM. $MMN,..~MMMO.
.?MMM. .MMM?.
OMMMMZ. .,NMMMN~
.IMMMMMM. .NMMMN. .MMMMMN,
,MMMMMM$..3MD..ZMMMMMM.
=NMMMMMM,. .,MMMMMMD.
.MMMMMMMM8MMMMMMM,
.ONMMMMMMMMMMZ.
,NMMMMMMM8.
.:,.$MMMMMMM
.IMMMM..NMMMMMD.
.8MMMMM: :NMMMMN.
.MMMMMM. .MMMMM~.
.MMMMMN .MMMMM?.
Atlassian JIRA
Version : 5.0.6
Detecting JVM PermGen support...
PermGen switch is supported. Setting to 256m
If you encounter issues starting or stopping JIRA, please see the Troubleshooting guide at http://confluence.atlassian.com/display/JIRA/Installation+Troubleshooting+Guide
Using JIRA_HOME: /Applications/Atlassian/atlassian-jira-5.0.6-standalone
Server startup logs are located in /Applications/Atlassian/atlassian-jira-5.0.6-standalone/logs/catalina.out
Using CATALINA_BASE: /Applications/Atlassian/atlassian-jira-5.0.6-standalone
Using CATALINA_HOME: /Applications/Atlassian/atlassian-jira-5.0.6-standalone
Using CATALINA_TMPDIR: /Applications/Atlassian/atlassian-jira-5.0.6-standalone/temp
Using JRE_HOME: /System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home
Using CLASSPATH: /Applications/Atlassian/atlassian-jira-5.0.6-standalone/bin/bootstrap.jar
Using CATALINA_PID: /Applications/Atlassian/atlassian-jira-5.0.6-standalone/work/catalina.pid
Opening up JIRA for the first time..
Having started JIRA on my localbox, I connected to port 8080 (the one I used as the default in the installation) and started to complete the setup:
It turns out I’ve made some sort of configuration/installation errors that was not called out in the documentation. Such is the story of software installation. I’ll have to get this one sorted out before continuing on. JIRA startup error.. this might take a little time to sort out my installation error.
Creating a dedicated JIRA user
Performing a little re-wind, I decided to create separate user account, that can be the JIRA home. This was suggested in the docs but I just didn’t grok it at the time (it’s after midnight.. some slack should be afforded). Created dedicated JIRA user.
Now.. back to the environment files… first I’m going to log into the new user and create a place for JIRA, copy it’s path, then update the configs.
I logged in to the new user, via the terminal window, then edited (creates actually) the .bash_profile for the user setting the following as the JIRA environment:
jira$ vi .bash_profile
## Required Element for JIRA
export JIRA_HOME=/Users/jira/jira-home
Next, I had to sort out one permissions issue in the Applications directory, and that had to do with the permissions to updates config files in the Altassian directory. To do this, I switched to my root user (su –), moved to the install directory and executed this command to allow group write at all the directory levels for the group user (in this case ‘staff’).
su
Password:
sh-3.2# pwd
/Applications/Atlassian/atlassian-jira-5.0.6-standalone
sh-3.2# chmod -R 775 *
I closed that terminal window, then logged my desktop into my new jira user and re-launched the configuration program (see above if you’ve forgotten how that is started up), and reset the home directory: Re-Setting the home directory
Tested the connection: Testing DB connection.
Set the ports I wanted to use for JIRA (defaults shown): Checking / Setting ports
Then kicked off JIRA again, but this time as the jira user. This time it stuck, took and started:
Next step 2 of the installation is presented, and the requisite settings defined. I’m going to run in PRIVATE mode, as I don’t want to have people attempt to add users to my JIRA without my permissions. That sounds like a licensing seat disaster in the making…. Step 2 of Setup.
NOTE: You will need to sign up and get an evaluation license key to go any further. Since I intend to purchase the product in the new future, unless the evaluation determines another course of action is required, this is a non-issue for me. You may be hesitant to do so, for some reason, one I won’t guess, but if so, be aware of that before digging yourself too deep a hole.
Two more quick steps follow, such as setting up your primary Admin User (sorry, NOT going to show you my settings there), and one last step confirming the setup was successful, before being shuttled over to your new Dashboard! Dashboard Login
And.. VIOLA!!! Notice the red warning at the far lowest left, the Evaluation DB attached is IN MEMORY only and most likely will be wrecked on a power fail or other shutdown. This could be a big issue on a laptop, wouldn’t you say? Regardless, this IS an evaluation after all…. so… next steps tomorrow will be to see how this all holds up over the next week when I’m back in CA and can install this on my office’s internal servers. Running, living, breathing JIRA!
Being an old-school OSS’er, MySql has been my go-to DB for data storage since the turn of the century. It’s great, I love it (mostly) but it does have it’s drawbacks. Largest of which is it’s now owned by Oracle which does a HORRIBLE JOB of supporting it. I have personal experience with this, as the results of a recent issue with InnoDB and MySQL.
In the mean time, some of the hot-shot up-and-commers in another department have been facing their own data processing challenges (with MySql and other DB’s), and have started to look at some highly scalable alternatives. One of the front-runners right now is Apache’s Cassandra database project.
The synopsis from the page is (as would be most marketing verbiage) very encouraging!
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data. Cassandra’s support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
This sounds too good to be true. Finally a solution that we might be able to implement and grow, and one that doe not have the incredibly frustrating drawback of InnoDB and MySql’s fragile replication architecture. I’ve found out exactly how fragile it is, despite have a cluster of high-speed specially designed DB servers, the amount of down time we had was NOT ACCEPTABLE!).
With a charter to handle ever growing amounts of data and the need for ultimate availability and reliability, an alternative to MySQL is almost certainly required.
Of the items discussed on the main page, this one really hits home and stands out to me:
Fault Tolerant
Data is automatically replicated to multiple nodes for fault-tolerance. Replication across multiple data centers is supported. Failed nodes can be replaced with no downtime.
I recently watched a video from the 2011 Cassandra Conference in San Francisco. A lot of good information shared. This video is available on the Cassandra home page. I recommend muscling through the marketing BS as the beginning and take in what they cover.
Job graph for ‘Big Data’ is skyrocketing.
Demand for Cassandra experts is also skyrocketing.
Big data players are using Cassandra.
It’s a known issue that RDBM’s (ex. MySql) have serious limitations (no kidding).
RDBM’s generally have an 8GB cache limit (this is interesting, and would explain some issues we’ve had with scalability in our DB severs, which have 64GB of memory).
The notion that Cassandra does not have good read speed, is a fallacy. Version 0.8 read speed is at parity of the already considered fast 0.6 write speed. Fast!?
No global or even low-level write locks. The column swap architecture alleviates the need for these locks, this allows high-speed writes.
Quorum reads and writes are consistent across the distribution.
New feature of local LOCAL_QUORUM allows quorums to be established from only the local nodes, alleviating latency waiting for a quorum including remote nodes in other geographic locations.
Cassandra uses XML files for schema modifications. In version 0.7 provides new features to allow on-line schema updates.
CLI for Cassandra is now very powerful.
Has a SQL language capability (yes!).
Latest version provides much easier to implement secondary indexing (indexes other than the primary).
Version 0.8 supports bulk loading. This is very interesting for my current project
There is wide support for Cassandra in both interpreted and compiled OSS languages, including the ones I most frequently use.
CQL Cassandra Query Language.
Replication architecture is vastly superior to MySQLs transaction and log replay strategy. Cassandra uses an rsync style replication where hash comparisons are exchanged to find which parts of the data tree a given replication node (that is responsible for that tree of data) might need updating, then then transferring just that data. Not only does this reduce bandwidth, but this implies asynchronous replication! Finally! Now this makes sense to me!!
Hadoop support exists for Cassandra, BUT, it’s not a great fit for Cassandra. Look into Brisk if Hadoop implementation is desired or required.
Division of Real-Time and Analytics nodes.
Nodes can be configured to communicate with each other in an encrypted fashion, but in general inter-node communication across public-private networks should be established using VPN tunnels.
This needs further research, but it’s very, VERY promising!
This just in…. (seems like a good thing). Notice that my new App CIDR Calculator for the MAC (in the wide for barely 24 hours now), was found by Softpedia, and linked in their site.
Congratulations,
CIDR Calculator, one of your products, has been added to Softpedia’s
database of software programs for Mac OS. It is featured with a description
text, screenshots, download links and technical details on this page: http://mac.softpedia.com/get/Utilities/DeMartini-CIDR-Calculator.shtml
The description text was created by our editors, using sources such as text
from your product’s homepage, information from its help system, the PAD
file (if available) and the editor’s own opinions on the program itself.
Nothing wrong with a little free exposure. No ratings so far, but I hope to get some good feedback. It’s already sold several units so I know someone is out there giving it a test.
If you want to learn more about this entry in Softpedia, [ HERE IS THE LINK ].
If you want to check out the App itself at the Apple MAC App Store.. just click on the button below!
 As with many MacOS’isms, you have to change up your old school LINUX to work with the slightly different command syntax of the MacOS tools. Specifically in the this case xargs and sed.
As with many MacOS’isms, you have to change up your old school LINUX to work with the slightly different command syntax of the MacOS tools. Specifically in the this case xargs and sed.